안드로이드에서 Enum 사용을 자제시킨 이유는?
ENUM의 각 값은 객체이며 각 선언은 객체를 참조하기 위해 런타임 메모리를 사용합니다.
따라서 ENUM 값은 Integer 또는 String 상수보다 많은 메모리를 사용합니다.
단일 ENUM을 추가하면 최종 DEX 파일의 크기 가 증가합니다. 또한 런타임 오버 헤드 문제가 발생하고 응용 프로그램에 더 많은 공간이 필요합니다.
Android에서 ENUM을 과도하게 사용하면 DEX 크기가 증가하고 런타임 메모리 할당 크기가 늘어납니다.
응용 프로그램이 더 많은 ENUM을 사용하는 경우 ENUM 대신 정수 또는 문자열 상수를 사용하는 것이 좋습니다.
String 객체 생성과 문자열 리터럴
String 생성 방법
- new 연산자를 이용한 방식
- 리터럴을 이용한 방식
1번 방식처럼 new 연산자를 사용하면 Heap 영역에 존재하게 되고 리터럴을 이용하면 String constant pool 영역에 존재하게 됩니다.
동작방식
리터럴로 선언하게 된 변수는 내부적으로 String의 intern() 메소드를 호출합니다. intern() 메소드는 주어진 문자열이 String constant pool에 있는지 검색 후 있다면 주소를 반환하고 없다면 String constant pool에 넣고 새로운 주소값을 반환하게 됩니다.
밑의 코드에서 s3.intern()을 하게 되면 먼저 String constant pool에 저장되어있던 s1의 주소를 불러오게 되므로 s1==s3가 true를 반환하게 됩니다.
equal 메소드와 ==의 차이
equal은 문자열을 비교합니다. 주소가 아닌 내용을 비교하기 때문에 문자열이 같다면 true를 반환하게 됩니다.
==은 주소를 비교합니다. 따라서, 문자열이 같아도 Heap영역에 있는 주소와 String constant pool에 있는 주소는 다르기 때문에 false를 반환하게 됩니다.
String s1 = "Hello";
String s2 = "Hello";
String s3 = new String("Hello");
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
System.out.println(s1 == s3); //false
System.out.println(s1.equals(s3)); //true
s3 = s3.intern();
System.out.println(s1 == s3); //true
System.out.println(s1.equals(s3)); //true
자바 어노테이션이란?
어노테이션은 본질적인 목적은 소스 코드에 메타데이터를 표현하는 것입니다. 단순히 부가적인 표현뿐만 아니라 리플렉션reflection을 이용하면 어노테이션 지정만으로도 원하는 클래스를 주입한다는지 하는 것이 가능합니다.
많이들 접한 @Override나 @SuppressWarningS 등 자바에서 기본으로 제공하는 어노테이션들이 있다.
또한 Meta 어노테이션으로 메타 어노테이션을 이용하여 커스텀 어노테이션을 만들 수 있습니다.
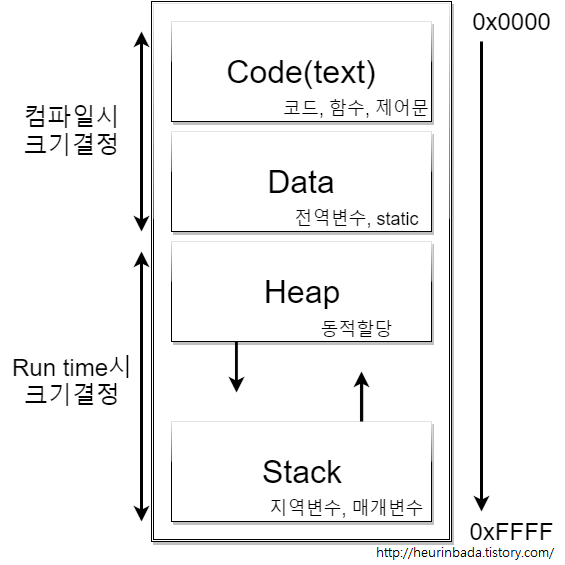
힙 메모리 영역과 스택 메모리 영역
프로그램이 시작되면 메모리 영역에 올라가게 됩니다. 메모리 영역에 올라온 프로그램들은 CPU의 명령을 통해서 실행되게 되는데 크게 4가지로 구분되어 메모리에 올라갑니다.
코드 영역 (Code Segment)
-
실제 프로그램 코드 자체가 적재되는 영역을 말합니다. C나 JAVA등의 개발 언어로 짜여진 프로그램은 컴퓨터가 이해할 수 있는 기계어의 형태로 컴파일 되어 파일 등에 저장되는데, 실제 이 파일의 프로그램에 대한 전체적인 코드 자체가 올라가는 영역입니다.
-
프로그램 자체 영역으로 보시면 됩니다.
데이터 영역 (Data Segment)
- 프로그램이 실행되면서 필요한 변수가 저장되는 영역인데, 이 데이터 영역은 프로그램이 구동되는 동안 항상 접근 가능한 변수가 저장되는 영역이라고 생각하시면 됩니다. 즉, 전역 변수(Global Variables)와 정적 변수(Static Variables)를 위한 할당 공간입니다.
스택 영역 (Stack Segment)
-
함수(또는 메서드, 프로시져 등) 내에 정의된 지역 변수(Local Variables)가 저장되는 영역입니다.
-
스택의 구조를 활용하여 함수의 지역 변수 메모리를 관리하면 위의 메커니즘을 쉽게 구현할 수 있기 때문에 스택 형태로 영역을 만들어 활용하였고, 그리하여 스택 영역(스택 세그먼트)라 이름이 붙었습니다.
힙 영역 (Heap Segment)
-
힙 영역은 위에서 관리가 가능한 데이터 외에 다른 형태의 데이터를 관리하기 위한 빈 공간(Free Space)입니다. 어떤 형태의 데이터가 있을까요? 바로 동적 할당(Dynamic Allocation)을 통해 생성된 동적 변수(Dynamic Variables)를 관리하기 위한 영역입니다.
-
힙 영역은 위의 다른 영역(데이터, 스택 등)을 모두 할당하고 남은 공간입니다. (남은 공간이라하여 딱히 영역에 제한이 있거나 그런 것은 아니고, 시스템의 메모리 공간 여유에 따라서 달라집니다.)
-
Java 나 C++ 등에서 ‘new’ 를 통해, C에서 ‘malloc’, ‘calloc’ 등을 통해 동적으로 생성되는 변수를 저장하기 위해 할당되는 영역이라고 생각하시면 됩니다.
-
데이터 영역과 스택 영역은 컴파일러가 미리 공간을 예측하고 할당할 수 있지만, 동적 변수는 어느 시점에 어느 정도의 공간으로 할당 될지 정확하게 예측할 수 없기 때문에 프로그램 실행 중(Runtime)에 결정됩니다.